¿Cuál fue el alcance de los estragos causados por el apagón masivo de Microsoft en el mundo?
Un error en la actualización de ciberseguridad de los sistemas de Microsoft derivó en una crisis mundial

Una falla informática global sin precedentes causó un gran caos en todo el mundo sin previo aviso el viernes: suspendió miles de vuelos, dejó estaciones de televisión fuera del aire y evitó que muchos pacientes pudieran ver a los médicos.
Los sistemas informáticos de Microsoft quedaron paralizados por una modesta actualización de seguridad que paralizó a algunas de las empresas más grandes del mundo y causó perturbaciones a gran escala. Incluso se comparó con el tan temido error del Milenio que no se materializó hace 24 años.
Las PC con Windows afectadas quedaron inutilizables y mostraron el mensaje de error de la “pantalla azul de la muerte”.
El director ejecutivo de CrowdStrike, la empresa que activó la actualización de software defectuosa, manifestó que lamentaba “profundamente” haberlo hecho, pero advirtió que tardaría “algo de tiempo” para que los sistemas se restablezcan por completo.
En Gran Bretaña, el caos incluyó:



- Aproximadamente 3.700 consultorios de médicos de cabecera (alrededor del 60 por ciento) se vieron afectados por la interrupción de las reservas de citas y otros servicios.
- El FTSE100 cayó un 0,8 por ciento.
- Se cancelaron casi 300 vuelos, de los casi 5.000 en todo el mundo.
- Casi todas las farmacias independientes sufrieron afectaciones.
- Sky News se incluye entre los canales que no pueden transmitir.
Las ramificaciones del error alcanzaron una escala nunca antes vista. Bancos, supermercados y otras instituciones informaron interrupciones, mientras que muchas empresas no pudieron aceptar pagos digitales ni acceder a bases de datos clave.
Los aeropuertos, que utilizan innumerables sistemas de PC para gestionar clientes y equipos, estuvieron entre los más afectados. En lo que iba a ser el día de mayor actividad en cinco años para los aeropuertos del Reino Unido, unos 50.000 pasajeros que planeaban volar hacia o desde Gran Bretaña el viernes se despertarán el sábado en un lugar en el que no tenían intención de estar.

Se formaron enormes colas en los aeropuertos afectados, y el personal de Gatwick se vio obligado a registrar manualmente a los pasajeros para los vuelos. El aeropuerto de Heathrow dijo el viernes por la tarde que todavía estaba “trabajando arduamente” para mejorar su funcionamiento y que los pasajeros “sigan su camino”.
En otra consecuencia dramática de la interrupción, CBBC y Sky News no pudieron transmitir el viernes por la mañana, y los presentadores de noticias se vieron obligados a usar notas impresas una vez que el canal volvió al aire después de más de una hora de apagón.
Y el secretario de salud, Wes Streeting, rogó a los pacientes que “tuvieran paciencia” a sus médicos de cabecera, ya que unas 3.700 consultas (alrededor del 60 por ciento de todas las cirugías) se vieron afectadas por interrupciones en la reserva de citas y la emisión de recetas.
Los servicios de ambulancia informaron de un “enorme” aumento de la demanda a medida que las personas también tenían dificultades para acceder a la aplicación del Servicio Nacional de Salud del Reino Unido (NHS), mientras que algunos hospitales sufrieron problemas administrativos. Royal Surrey NHS Foundation Trust declaró un incidente crítico y canceló las citas de radioterapia.
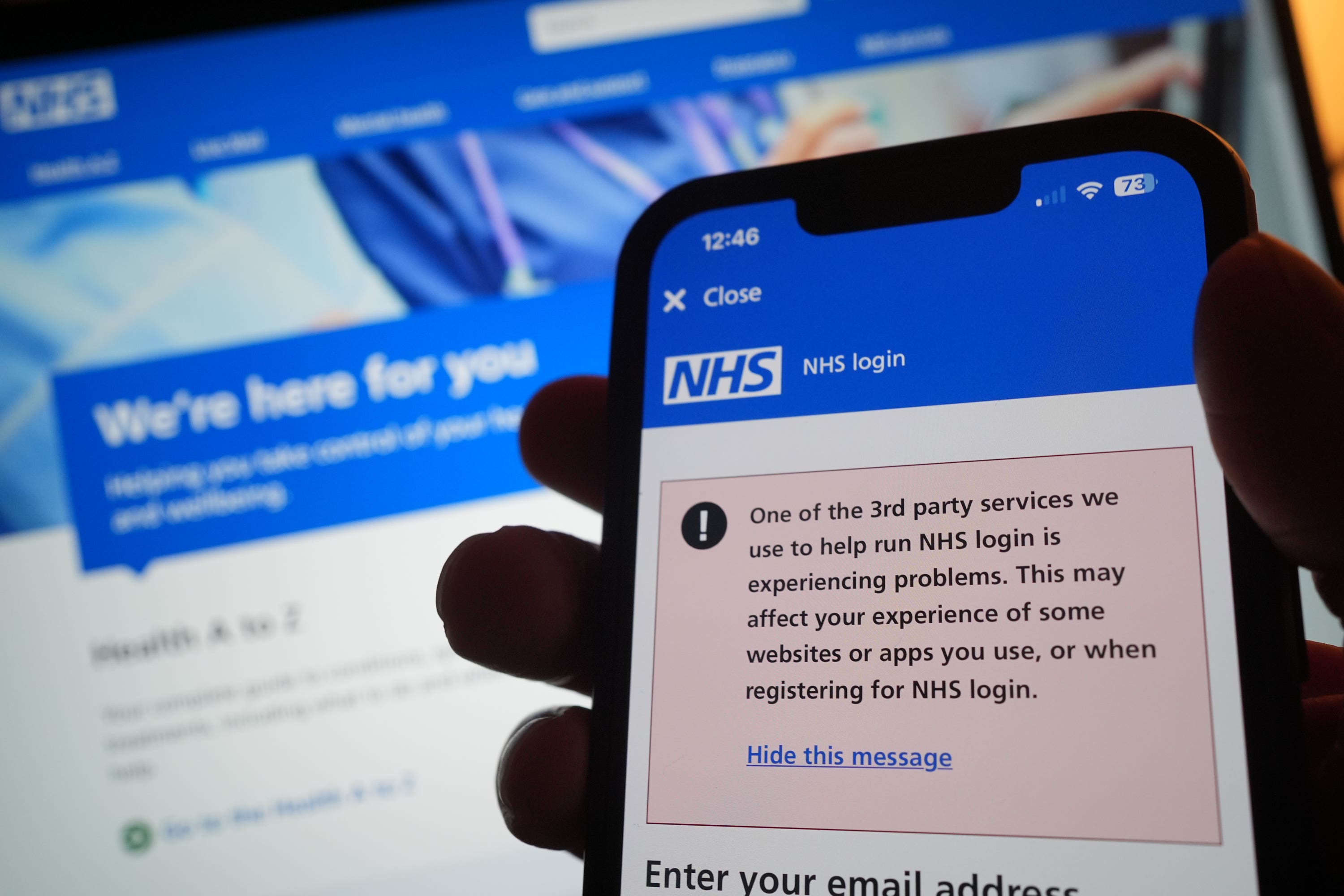
La Asociación Nacional de Farmacias, que representa a muchas de las 9.000 farmacias de la comunidad independiente del Reino Unido, informó a The Independent que la interrupción estaba afectando “a casi todos nuestros miembros de alguna manera”.
Govia Thameslink Railway, el operador de trenes más activo del Reino Unido, que opera los servicios Southern, Thameslink, Gatwick Express y Great Northern alrededor de Londres, también aseveró que estaba presentando “problemas generalizados de TI”.
El sitio web de seguimiento Down Detector registró interrupciones y problemas en una gran variedad de otras empresas, incluidas Visa, Mastercard, Amazon, Ryanair, Ladbrokes y BT.
La crisis mundial “no tiene precedentes en la variedad y escala de los sistemas a los que ha afectado”, advirtió el Dr. Harjinder Lallie, experto en ciberseguridad y profesor asociado de la Universidad de Warwick.
“Nunca antes había visto algo así”, sostuvo el Dr. Lallie. “Tuvimos el ataque de ransomware al NHS, WannaCry, que fue grave. Pero esto involucra aviones, estaciones de televisión, es un impacto enorme”.

El Dr. Lallie advirtió que “esta ‘catástrofe’ de TI destaca la necesidad de una mayor resiliencia, un mayor enfoque en los sistemas de respaldo y posiblemente incluso la necesidad de repensar si estamos utilizando los sistemas operativos más resistentes para sistemas tan críticos”.
Dado que muchos minoristas de todo el mundo informan problemas con los pagos digitales, Andrew Goodacre, jefe de la Asociación Británica de Minoristas Independientes, planteó a The Independent que los principales problemas de TI parecen estar ocurriendo “con demasiada frecuencia”.
“Los minoristas independientes no tienen el tipo de recursos que se pueden encontrar en una cadena grande, pero aun así necesitan el mismo nivel de protección. Puede hacerlos más vulnerables cuando ocurren fallas de TI”, señaló.
Si bien no está claro cuántos minoristas se vieron afectados en general, un portavoz del British Retail Consortium confirmó que la mayoría reanudó sus operaciones con normalidad.

CrowdStrike, que proporciona monitoreo y protección contra ataques cibernéticos a muchas empresas importantes, explicó que el problema fue causado por un “defecto encontrado en una única actualización de contenido para hosts de Windows”, y agregó que no se trataba de un incidente de seguridad o ciberataque.
El valor de sus acciones cayó un 12 por ciento en las primeras operaciones del viernes, después de que Elon Musk lo calificara como el “mayor fracaso de TI de la historia”.
El director ejecutivo, George Kurtz, expresó: “Lamentamos profundamente el impacto que hemos causado a los clientes, a los viajeros y a cualquier persona afectada por esto”.
“Hemos estado en contacto con nuestros clientes toda la noche y trabajando con ellos; muchos de nuestros clientes están reiniciando el sistema y está funcionando porque lo arreglamos de nuestro lado. Estamos trabajando con algunos de los sistemas que no se recuperan, por lo que podría pasar algún tiempo para algunos sistemas que simplemente no se recuperan de manera automática. Nuestra misión es asegurarnos de que todos los clientes estén completamente restablecidos y no vamos a ceder hasta que todos los clientes vuelvan a donde estaban y continuaremos protegiéndolos y manteniendo a los malos fuera de sus sistemas”.
Añadió: “El software es un mundo muy complejo y hay muchas interacciones, y estar siempre por delante del adversario es una tarea ardua”.
Adam Leon Smith de BCS, The Chartered Institute for IT, advirtió que podrían pasar incluso “semanas” para que todas las computadoras y sistemas se restablezcan por completo: “La solución tendrá que aplicarse a muchas computadoras en todo el mundo”.
“Entonces, si las computadoras tienen pantallas azules y bucles interminables, podría ser más difícil y tardar días y semanas.”
El profesor Ciaran Martin, director ejecutivo fundador del National Cyber Security Centre (NCSC), observó que el incidente fue una “demostración increíblemente poderosa de nuestras vulnerabilidades digitales globales y la fragilidad de la infraestructura central de Internet”.
Según el profesor Martin, que ahora trabaja en la Universidad de Oxford, es difícil estimar cuánto tiempo tardaría recuperarse de la interrupción.
“Se solucionó el problema subyacente y se están implementando las soluciones. Algunas industrias pueden recuperarse con rapidez. Pero otros, como la aviación, tendrán largos retrasos. Dicho esto, me sorprendería que todavía tuviéramos problemas graves la próxima semana a esta hora”.
Añadió que la industria cibernética también necesitaba mejorar en “encontrar y solucionar estos puntos únicos de falla en toda la infraestructura digital central”.



Traducción de Michelle Padilla
Bookmark popover
Removed from bookmarks