Experto advierte: la inteligencia artificial enfrenta escasez de datos para entrenarse
Según el jefe de datos de Goldman Sachs, la escasez de información para entrenar IA podría generar un “estancamiento creativo”

Los modelos de inteligencia artificial como ChatGPT (OpenAI) y Gemini (Google) enfrentan un obstáculo inesperado: la falta de datos para seguir entrenando sus modelos.
Así lo advirtió Neema Raphael, director de datos de Goldman Sachs, quien alertó en el pódcast Exchanges que la inteligencia artificial “ya se ha quedado sin datos”.
Según dijo, los modelos comienzan a depender de información sintética, creada por las propias máquinas, un fenómeno que podría ralentizar la innovación.
“Quizás veamos lo que algunos llamarían un estancamiento creativo. Si los modelos se alimentan solo de datos generados por la propia IA, ¿qué lugar ocuparán entonces los datos humanos? Esa tensión será clave de seguir, incluso desde una óptica filosófica”.
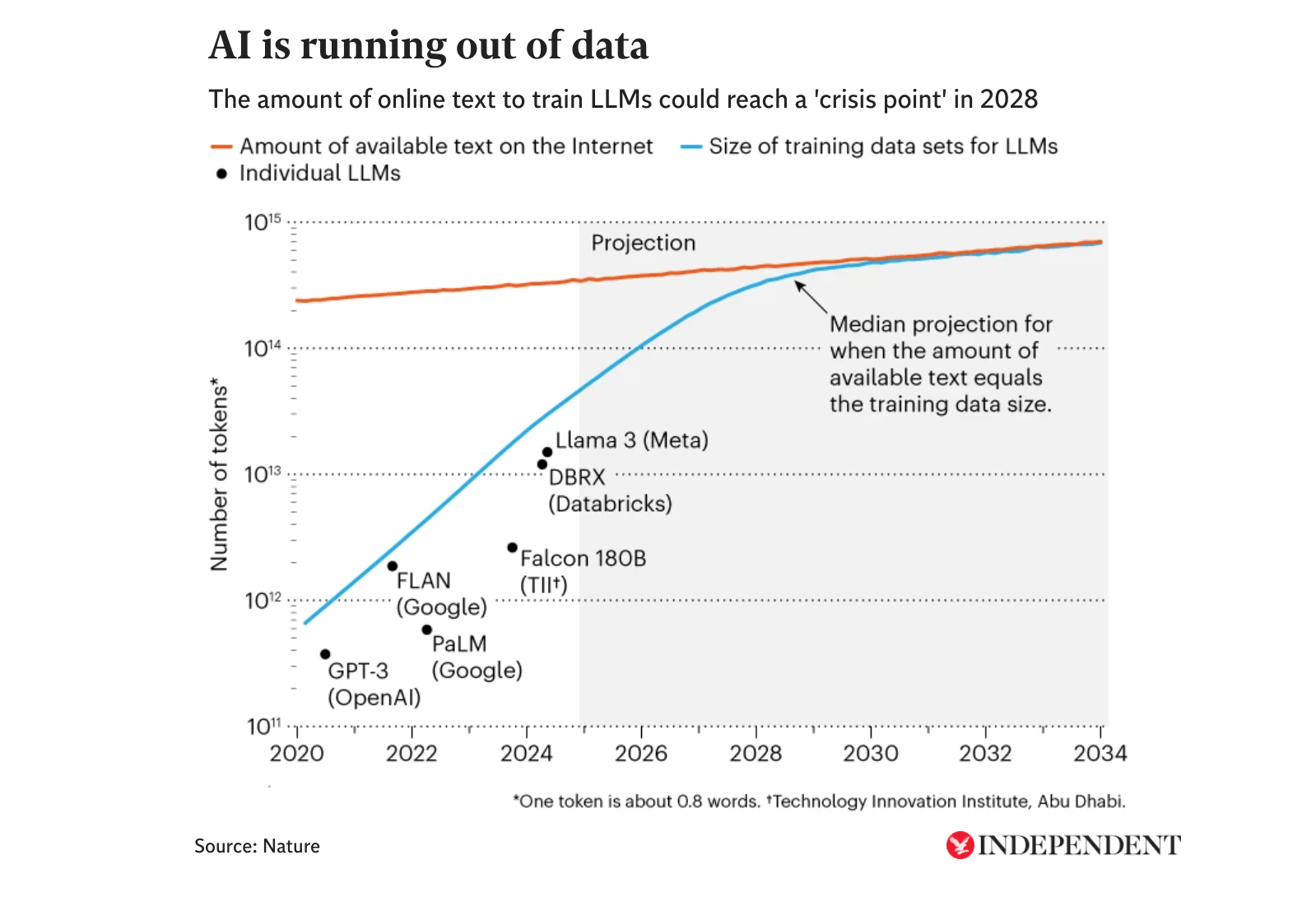



No es la primera vez que voces influyentes de la industria advierten sobre el llamado “pico de datos”, un escenario en el que los modelos de inteligencia artificial consumen casi todo el contenido disponible en internet.
En diciembre, la revista Nature predijo que este “punto de crisis” podría alcanzarse en 2028: “Internet es un vasto océano de conocimiento humano, pero no es infinito. Los investigadores en inteligencia artificial prácticamente lo han agotado”, se señalaba en el artículo.
El cofundador de OpenAI, Ilya Sutskever, ya había alertado el año pasado que la falta de datos de entrenamiento significará que el rápido desarrollo de la IA “terminará indudablemente”.
Para él, los datos son como los combustibles fósiles: un recurso finito, comparable al petróleo o el carbón.
“Hemos alcanzado el pico de datos y no habrá más. Tenemos que trabajar con lo que ya existe. Solo hay un internet”, afirmó.
La falta de nuevos insumos podría forzar a las compañías de inteligencia artificial a abandonar los modelos de entrenamiento tradicionales y desplazar su atención de los grandes modelos de lenguaje, como ChatGPT, hacia formas más avanzadas de IA agentiva.



Estos agentes de inteligencia artificial, ya en desarrollo por las principales firmas del sector, se conciben como sistemas autónomos capaces de tomar decisiones y ejecutar tareas en línea sin supervisión humana.
Traducción de Leticia Zampedri
Bookmark popover
Removed from bookmarks